Vulnerability Overview
V8 is the JavaScript engine in the Chromium kernel, responsible for interpreting, optimizing, and executing JavaScript code. CVE-2020-16040 (crbug.com/1150649) is an integer overflow vulnerability generated by the V8 optimization compiler Turbofan in the SimplifiedLowering phase.
Vulnerability Analysis
1) What is Turbofan?
The following is the workflow of the V8 engine:
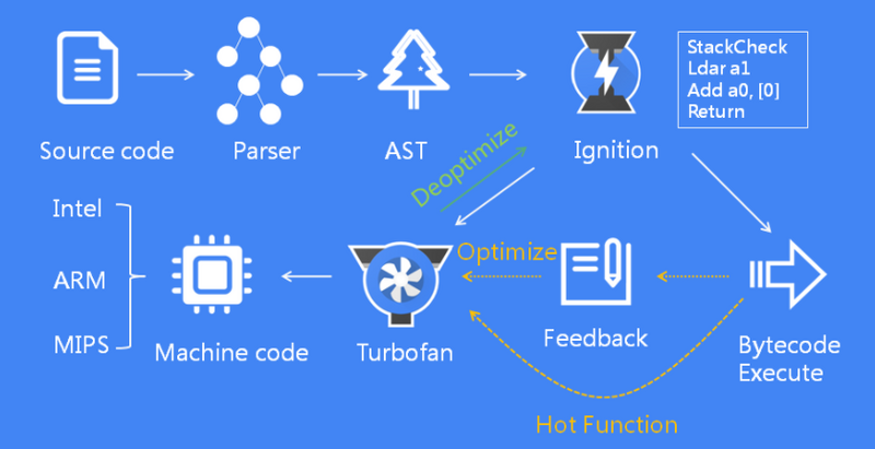
Parser: Responsible for analyzing the syntax errors of the source code, converting it into an AST abstract syntax tree, and determining the lexical scope by using the tokens obtained through lexical analysis of the source code:

Ignition (Interpreter): Responsible for converting AST into intermediate code, namely bytecode, and interpreting and executing the bytecode line by line. At this stage, the JavaScript code has already begun to execute.
Consider the following code bytecode.js:
1 | let ziwu_add = (x,y) => { |
Use the command ./d8 bytecode.js --allow-natives-syntax --print-bytecode --print-bytecode-filter ziwu_add to get its bytecode:
1 | [generated bytecode for function: ziwu_add (0x1984082d26e1 <SharedFunctionInfo ziwu_add>)] |
TurboFan (optimizing compiler):Responsible for taking bytecode and some analysis data as input and generating optimized machine code. When Ignition converts JavaScript code into bytecode, the code starts to execute. V8 will keep observing the execution of JavaScript code and record execution information, such as the number of executions of each function, the type of parameters passed each time the function is called, etc. If the number of times a function is called exceeds the internal threshold, the monitor will mark the current function as a hot function and send the bytecode of the function and related information about the execution to TurboFan. TurboFan will make some assumptions to further optimize this code based on the execution information, and compile the bytecode into optimized machine code based on the assumptions. If the assumption is true, then the next time the function is called, the optimized compiled machine code will be executed to improve the execution performance of the code. When the information passed in during a call changes, it means that TurboFan’s assumption is wrong. At this time, the machine code generated by the optimized compilation can no longer be used, so the optimization is rolled back and the original complex function logic is re-run.
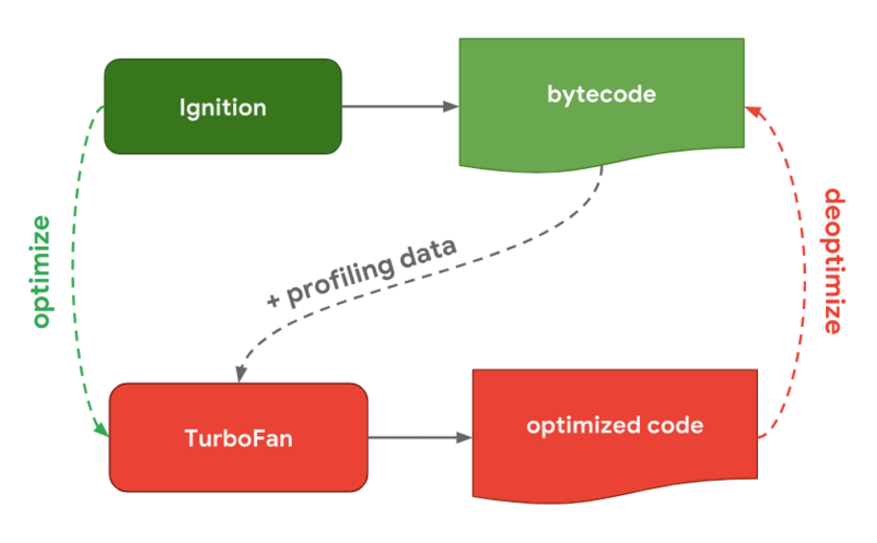
The optimization logic process is as follows, considering the following code:
1 | let ziwu_add = (x,y) => { |
V8 needs to determine the types of x and y before performing each calculation, and then perform the corresponding processing, but what if the function needs to be executed many times?
1 | let ziwu_add = (x,y) => { |
The x parameter keeps changing. If we have to judge the type every time, it will be too cumbersome and inefficient. Turbofan found that after so many loop calculations, the x and y parameters are both int types. We have reason to believe that it will be the same next time. So we can assume that the types of the x and y parameters are int. Based on this assumption, we can optimize the ziwu_add function to simple addition:
add eax ebx;
2) Vulnerability Recurrence
First look at the vulnerability patch: https://chromium.googlesource.com/v8/v8.git/+/ba1b2cc09ab98b51ca3828d29d19ae3b0a7c3a92, the vulnerability file is located atsrc/compiler/simplified-lowering.cc, that is, the vulnerability may occur in the SimplifiedLowering stage of the Turbofan optimization process;
We switch the V8 version to its parent commit, which is the most recent V8 code branch version where the vulnerability exists. The operation method is not described here:

Execute the PoC code ./d8 –allow-natives-syntax poc.js:
1 | function foo(a) { |
The result we get is:
1 | True |
The two execution results of the foo(false) function are different, indicating that there is a problem in the calculation of the value of z in the Turbofan optimization process.
3) Principle analysis
Principle brief description:This vulnerability is actually caused by the inconsistency between the maximum value range (restriction_type) calculated when optimizing the SpeculativeSafeIntegerAdd node in the VisitSpeculativeIntegerAdditiveOp function and its own Type, which results in an incorrect type transfer during the subsequent SpeculativeNumberLessThan node optimization process, causing SpeculativeNumberLessThan to be incorrectly optimized to Uint32LessThan. As a result, incorrect constant folding occurs in the EarlyOptimization phase, resulting in inconsistency with the calculation before optimization.
Detailed analysis:
1. Analysis of the reason why the foo(false) function is executed as True before optimization:
1) y = 0x7fffffff, which is the maximum 32-bit integer, z = (0x7fffffff +1) | 0
2) Since the bitwise AND operation treats its operands as 32-bit sequences (consisting of 0s and 1s), (0x7fffffff + 1) = -2147483648
3) z = -2147483648|0, z must be less than 0, and the result of executing the foo function is true
2. Calculation error occurred during Turbofan optimization:
We first use a for loop to force trigger Turbofan’s optimization:
1 | for (i=0;i<0x10000;i++){ |
The Turbofan optimization process will first enter the SimplifiedLowering stage, which determines the input type, output type, maximum value range, etc. of each node in the Bytecode Graph Tree through forward and reverse traversal. It is divided into three sub-stages: Propagate, Retype, and Lower[1].
Let’s first look at how SimplifiedLowering optimizes our foo function in this example:
1)Propagate stage: We can use ./d8 --allow-natives-syntax poc.js --trace-representation to view the Propagate process of the entire PoC script:
1 | --{Propagate phase}-- |
This stage is a reverse analysis, from the End node to the Start node, determining the required type based on the Type of the input node, and associating the use information (UseInfo) with the relevant node. And marking the output type of the node as the maximum range restriction_type of the output.
During the optimization of the foo function, the kSpeculativeNumberBitwiseOr#45 node is accessed first, as shown in the following figure:
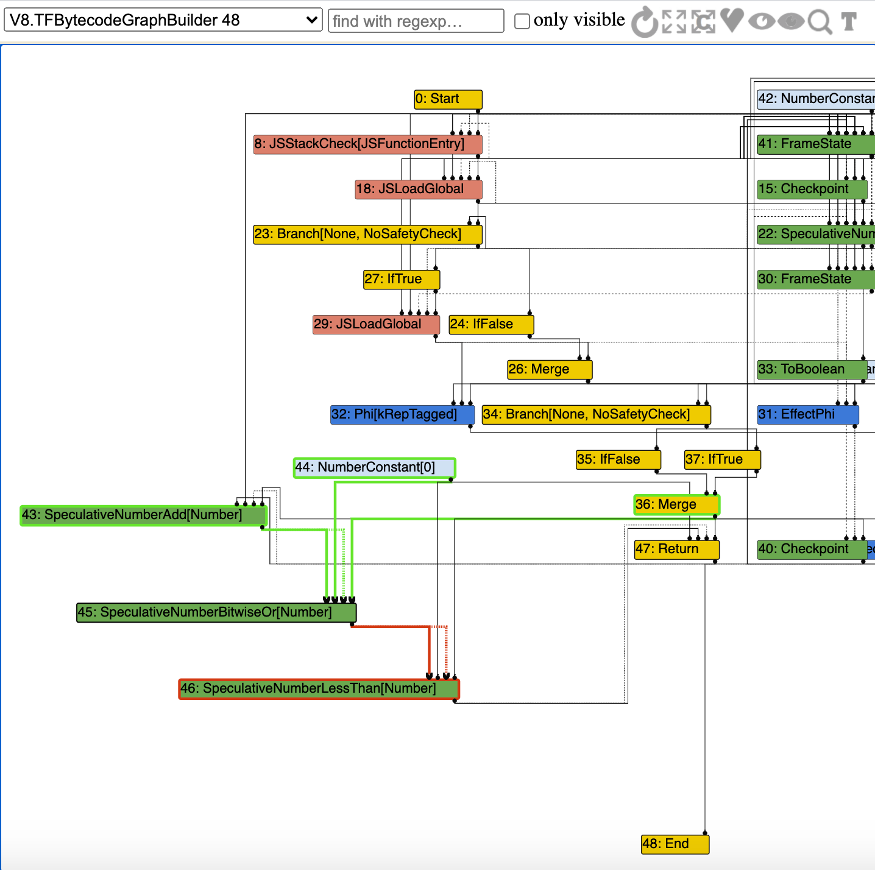
According to the code logic of src/compiler/simplified-lowering.cc, the VisitSpeculativeInt32Binop function is called. Since the two input nodes #43/#44 of node #45 are both of Number type, the BothInputsAre(node, Type::NumberOrOddball()) condition is met, and then turbofan marks #43/#44 as UseInfo::TruncatingWord32():
1 | case IrOpcode::kSpeculativeNumberBitwiseOr: |
Then continue to visit the SpeculativeSafeIntegerAdd#43 node. Since we expanded the type of the input y of this node in the PoC if (a == NaN) y = NaN;that is, the #39 node has the NaN type, we can observe this phenomenon through the –trace-representation option:
1 | \#39:Phi[kRepTagged](#32:Phi, #38:NumberConstant, #36:Merge) [Static type: (NaN | Range(-1, 2147483647))] |
Therefore, the if condition in the src/compiler/simplified-lowering.cc::VisitSpeculativeIntegerAdditiveOp function is not met, and the maximum value range of restrict_type is set to Signed32(), that is, -2147483648 ~2147483647
1 | void VisitSpeculativeIntegerAdditiveOp(Node* node, Truncation truncation, |
But we can observe that the Type of SpeculativeSafeIntegerAdd#43 node is 0 ~ 2147483648
1 | \#43:SpeculativeSafeIntegerAdd[SignedSmall](#39:Phi, #42:NumberConstant, #22:SpeculativeNumberEqual, #36:Merge) [Static type: Range(0, 2147483648), Feedback type: Range(0, 2147483647)] |
2)Retype stage: Similarly, we can continue to use –trace-representation to view the Retype process:
1 | --{Retype phase}-- |
It can be seen that this stage is a forward analysis, from the End node to the Start node, it is sequentially put into the stack, and then starting from the top of the stack, it visits and determines the output type according to the Type and restriction_type of the input node, and uses UpdateFeedbackType to update the type of each node, and calculates the output representation of each node input.
Turbofan first visits the SpeculativeSafeIntegerAdd#43 node and enters the src/compiler/simplified-lowering.cc::UpdateFeedbackType function logic. The opcode of this node is IrOpcode::kSpeculativeSafeIntegerAdd:
According to src/compiler/opcodes.h
1 | \#define SIMPLIFIED_SPECULATIVE_NUMBER_BINOP_LIST(V) \ |
Then, the logic at the following mark is entered, and the types of the two input nodes #39 and #42 of the #43 node are calculated by SpeculativeSafeIntegerAdd, and then the intersection operation (Intersect) is performed with the restriction_type of the node itself.
1 | bool UpdateFeedbackType(Node* node) { |
Enter src/compiler/operation-typer.cc::OperationTyper::SpeculativeSafeIntegerAdd function:
1 | Type OperationTyper::SpeculativeSafeIntegerAdd(Type lhs, Type rhs) { |
That is, the value range of node #43 is 0 ~ 0x7fffffff, which is Unsigned32
Then visit the SpeculativeNumberBitwiseOr#45 node. According to the type of input nodes #43/#44, the result is still 0 ~ 0x7fffffff, that is, the value range of z in PoC is considered to be 0 ~ 0x7fffffff
3)Lower stage: Similarly, we can continue to use –trace-representation to view the Lower process
1 | --{Lower phase}-- |
We can see that this stage mainly does two things:
- Optimize the node itself into a more specific node through DeferReplacement
- Use the ConvertInput conversion node when the output representation (obtained by the Retype stage) of a node input does not match the expected use information (UseInfo) of its input.
Turbofan accesses the SpeculativeNumberLessThan#46 node and enters the following logic in src/compiler/simplified-lowering.cc:
1 | case IrOpcode::kNumberLessThan: |
Since the left input node #45 (z in the PoC code) and the right input node number 0 are both Unsigned32OrMinusZero, if the condition is met, Uint32Op(node) is called
Refer to src/compiler/simplified-lowering.cc::Uint32Op
1 | const Operator* Uint32Op(Node* node) { |
Enter the Uint32OperatorFor logic, the source code is located in src/compiler/representation-change.cc
1 | const Operator* RepresentationChanger::Uint32OperatorFor( |
Therefore node #46 is converted to Uint32LessThan
4)Vulnerability trigger: EarlyOptimization stage
Enter the code src/compiler/machine-operator-reducer.cc logic
1 | case IrOpcode::kUint32LessThan: { |
Since the right input node of node #46 (i.e. z<0 in PoC) is 0, the m.right().Is(0) condition is satisfied, and the result of the expression is judged to be false.
Analysis of the reason why the foo(false) function is executed as False after optimization:
Combined with the analysis in the second step, after turbofan optimization, the expression z<0 is incorrectly judged as false, so the foo(false) function returns false.
Vulnerability Summary
This vulnerability is a typical logic vulnerability caused by the turbofan optimization process. It is relatively easy to debug and is suitable for V8 beginners. Understanding it through the source code will have a good effect. V8 has many similar vulnerabilities in recent years, such as crbug.com/880207. If you are interested, you can go to debug and learn.
If there are any inappropriate parts in the text, please correct me. We welcome your comments.
Reference Links
[1]Modern attacks on the Chrome browser: optimizations and deoptimizations: https://buaq.net/go-45470.html
[2] Vulnerability fix code: https://chromium.googlesource.com/v8/v8.git/+/ba1b2cc09ab98b51ca3828d29d19ae3b0a7c3a92